

ここでは、「scikit-learn」を用いた機械学習について解説しています。
この記事の対象
scikit-learnとは
「scikit-learn(サイキット・ラーン)」とは機械学習のフレームワークの1つです。
分類器が豊富に用意されており、学習結果を検証する機能があったりと、最もポピュラーなものとして知られています。
scikit-learnでできること
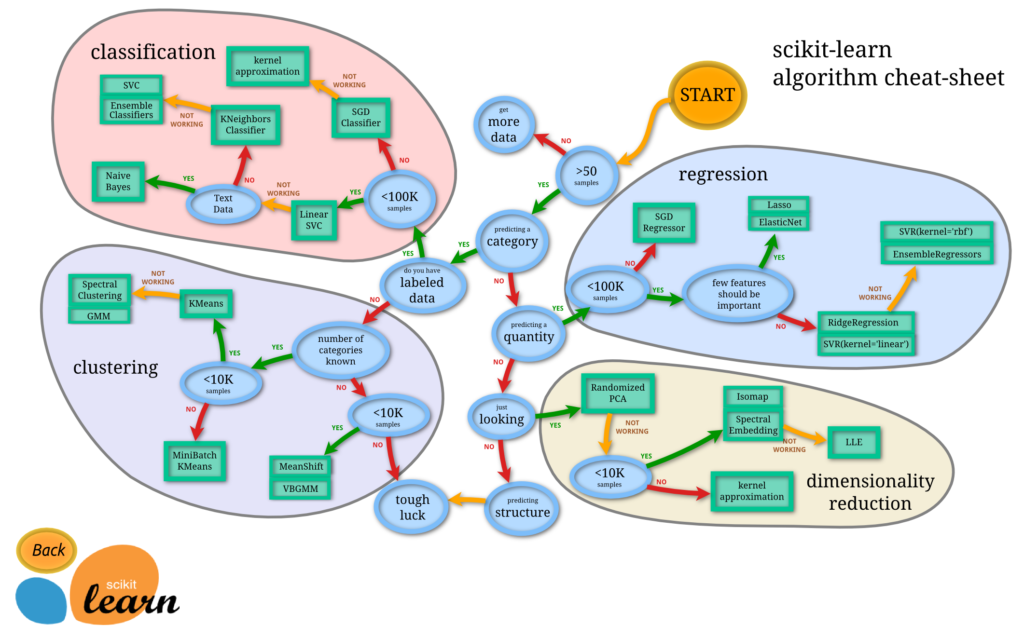
「scikit-learn」では、分類、回帰、クラスタリング、次元削減が可能です。
上記の図は、公式サイトにある、Data内容から適切な解析方法へのアプローチを示しています。scikit-learnを用いる際、迷ったら参考にするべきものです。
注意するべき点は、深層学習についてはカバーしていないのでTensorflow、Kerasなどを利用する必要があります。
scikit-learnを用いた使用例
ここでは、シンプルな例として、BMIを用いたSVMの学習を紹介しています。
SVMを用いた使用例
scikit-learnでのSVMの分類は以下の通りです。
- SVC
- LinerSVC
- NuSVC
以下では「SVC」を使用しています。
プログラムの流れ
- 用意したBMIデータの読込
- データの正規化
- 学習用とテスト用にデータを分割
- 学習
- 予測
- 可視化
入力データ(BMIデータ)
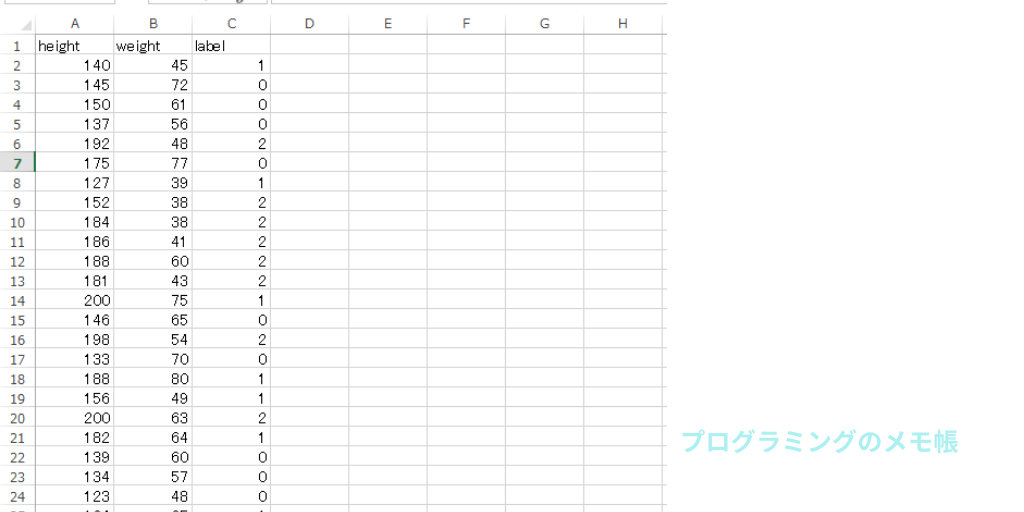
今回使用したデータは予め自分でheight,weight,labelを定義して、体重と身長をrandom関数で生成しました。加えて、その結果を基にしてBMI値(= weight / height * height)を算出したものになります。
labelの意味としては、算出したBMI値をx<18.5をthin,18.5<x<25をnormal,それ以外をfatとしています。labelの意味は以下の通りです。
fat = 0
normal = 1
thin = 2
プログラム
from sklearn import model_selection, svm, metrics
import matplotlib.pyplot as plt
import pandas as pd
from mlxtend.plotting import plot_decision_regions
import numpy as np
#1---データ読込
predata = pd.read_csv("bmi.csv")
#2---正規化
w = predata["weight"] / 120
h = predata["height"] / 200
wh = pd.concat([w, h], axis=1)
#3---学習用とテスト用データに分割
data_train, data_test, label_train, label_test = \
model_selection.train_test_split(wh, predata["label"])
#4---学習
clf = svm.SVC()
clf.fit(data_train, label_train)
#5---予測
predict = clf.predict(data_test)
#6---結果確認
ac_score = metrics.accuracy_score(label_test, predict)
cl_report = metrics.classification_report(label_test, predict)
print("正解率=", ac_score)
print("レポート=\n", cl_report)
#7---決定境界の可視化
x_combined = data_train.iloc[:, [0,1]].values
y_combined = label_train.values
clf.fit(x_combined, y_combined)
plot_decision_regions(x_combined, y_combined, clf=clf)
#8---保存
plt.savefig("image.png")
plt.clf()
plt.close()学習と予測だけに着目するとたった数行だけで実行できてしまうのが、scikit-learnの特徴になります。
しかし、実際には線形的な比較的分かりやすいデータであっても前処理や出力結果の可視化などをすると数十行になってしまうという結果です。
それでは、解説していきます。
#1---データ読込
predata = pd.read_csv("bmi.csv")1の部分ではデータの読込みを行っています。全てのデータをpandasで読込んでいます。
#2---正規化
w = predata["weight"] / 120
h = predata["height"] / 200
wh = pd.concat([w, h], axis=1)2の部分では、読込んだデータの「weight」「height」を正規化しています。
正規化については以下をご参照下さい。
#3---学習用とテスト用データに分割
data_train, data_test, label_train, label_test = \
model_selection.train_test_split(wh, predata["label"])3の部分では、データを学習用とテスト用に分割しています。「model_selection.train_test_split」はscikit-learnの関数で自動でデータを分割してくるものになります。引数で特に指定しない限りは、25%がテスト用、75%が訓練用になります。
#4---学習
clf = svm.SVC()
clf.fit(data_train, label_train)4の部分では、学習させています。今回は「SVC」を選択しています。デフォルトではRBFカーネルで、C=1.0, gamma= 1/特徴数となっています。fitでデータを学習させています。
#5---予測
predict = clf.predict(data_test)5の部分ではテストデータを予測しています。
#6---結果確認
ac_score = metrics.accuracy_score(label_test, predict)
cl_report = metrics.classification_report(label_test, predict)
print("正解率=", ac_score)
print("レポート=\n", cl_report)6の部分では結果を確認しています。「metrics.accuracy_score」は分類精度を評価する関数です。「metrics.classification_report」は予測のレポートを出力する関数です。
#7---決定境界の可視化
x_combined = data_train.iloc[:, [0,1]].values
y_combined = label_train.values
clf.fit(x_combined, y_combined)
plot_decision_regions(x_combined, y_combined, clf=clf)7の部分では「plot_decision_regions」で予測の結果を画像化しています。引数には特徴量データと分類データを割り当てています。
結果
正解率= 0.993
レポート=
precision recall f1-score support
0 1.00 0.99 1.00 1921
1 0.98 0.99 0.99 1513
2 1.00 0.99 0.99 1566
accuracy 0.99 5000
macro avg 0.99 0.99 0.99 5000
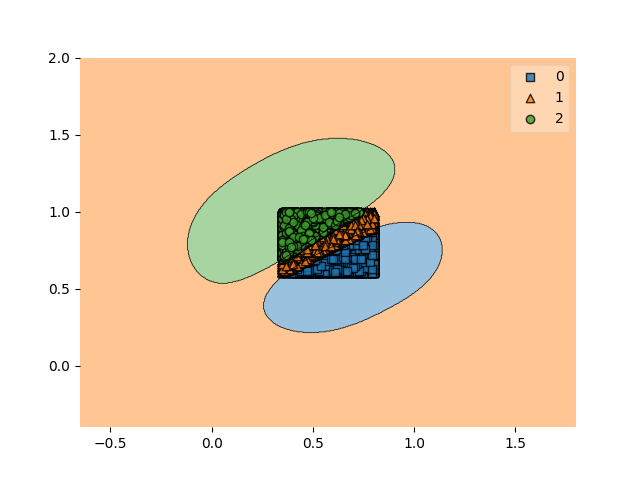
weighted avg 0.99 0.99 0.99 5000結果としては、0.993という正解率で振り分けることができました。
可視化した結果からは、データがはっきりとしたものであったことにより、きれいな分類分けができました。
gammaを指定して調整
#4---学習
clf = svm.SVC(gamma='auto')ガンマを指定するとだいぶ変わりました。パラメータの重要性が分かる結果となりました。ガンマの値が小さいと単純な決定境界、大きいと複雑な決定境界になるようです。
【結果】
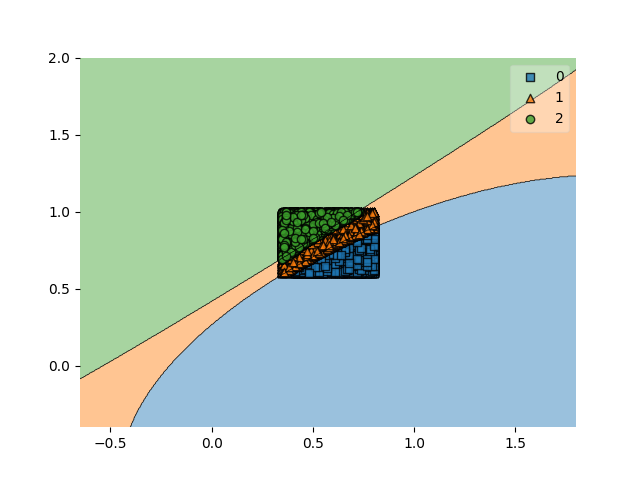
Cを指定して調整
clf = svm.SVC(C=0.5,kernel='linear')ソフトマージンのCを0.5、kernelをlinearに指定しました。また、出力のX軸、Y軸を調整しました。
plot_decision_regions(x_combined, y_combined, clf=clf)
#表示範囲指定
plt.xlim(0, 1)
plt.ylim(0, 1.5)
#保存
plt.savefig("test.png")
plt.clf()
plt.close()【結果】
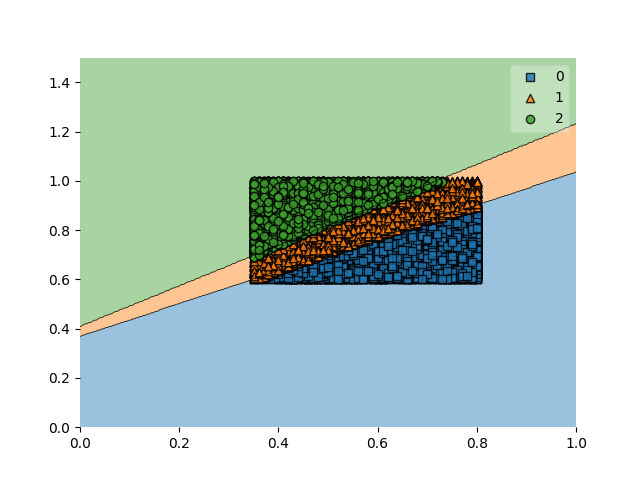
その他、scikit-learnを用いた使用例
| 項目 | 内容 |
| 【機械学習入門】正規化なしでの株価の機械学習を行ってみた | 「scikit-learn」を用いてニコンの株価データ10年分を機械学習させてみました。 |