
ここでは、Pythonにおける「TechCrunch」の記事タイトルをスクレイピングする方法について解説しています。
行ったこと
「TechCrunch」の記事タイトルをスクレイピングして出力できるようにしました。
プログラム
from bs4 import BeautifulSoup
import requests
import openpyxl
#1---URL指定
url = "https://jp.techcrunch.com/"
#2---headers指定
headers = {"User-Agent": ""}
soup = BeautifulSoup(requests.get(url, headers = headers).content,'html.parser')
#3---h3タイトルの抽出
all_h3 = soup.select('h2')
for i in range(1,len(all_h3)):#5つ抽出
cell = all_h3[i].get_text()
print(cell)
#4---終了の合図
print('完了')上記がプログラムになります。
それでは解説していきます。
#1---URL指定
url = "https://jp.techcrunch.com/"スクレイピングしたいサイトのURLを指定しています。
#2---headers指定
headers = {"User-Agent": ""}
soup = BeautifulSoup(requests.get(url, headers = headers).content,'html.parser')headersを指定しています。「確認くん」などで現在使用しているブラウザ環境を記載します。「確認くん」における、「現在のブラウザ」を「*****」に転記してください。
次にURLとheaderをBeautifulSoupに投げています。これでhtmlを解析して次で指定している「h2」を抽出します。
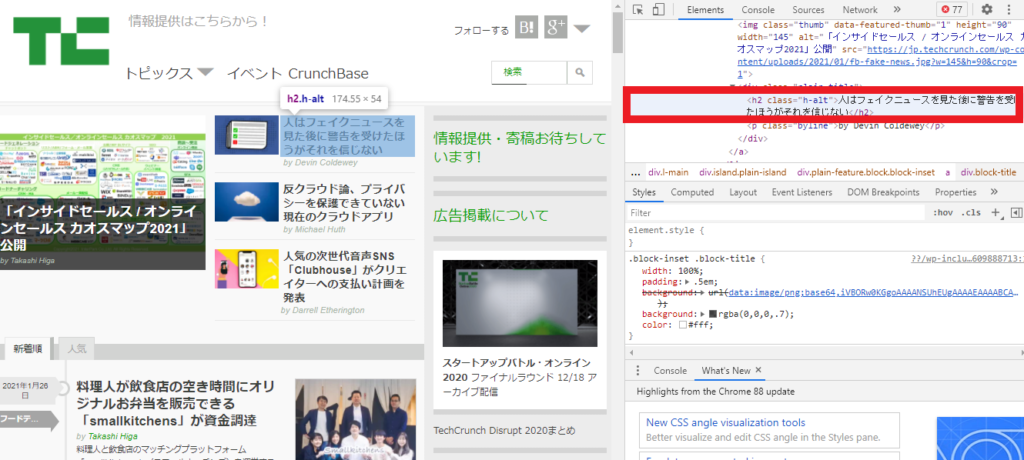
#3---h2タイトルの抽出
all_h2 = soup.select('h2')
for i in range(1,len(all_h2)):#リスト抽出
cell = all_h2[i].get_text()
print(cell)3の部分では、「h2」を抽出しています。次に、見つけたh2要素を全て出力するようにfor構文で指定しています。
最後に完了した合図を出力しています。
結果

h2要素を全て出力した結果です。
欲しい情報だけをメールやLineなどに飛ばして独自のRSSにするなど、色々と工夫できそうですね。
色々と試していきます。