

Webスクレイピングを学習していると、テキストだけでなく「画像を自動で集めたい」と思うことがあります。
そんなときに便利なのが iCrawler というPythonライブラリです。
この記事では、初心者向けにインストールから基本コード、応用例(Google画像検索から一括ダウンロード)までを解説します。
この記事の対象
icrawlerとは
「icrawler」とはウェブクローラのライブラリであり、画像や動画を簡単にスクレイピングできるものです。
外部ライブラリなので、以下の様にpipでインストールしておく必要があります。
$ pip install icrawler対応しているものとして以下があります。
行ったこと
とあるアイドルの画像を一括でスクレイピングしてみました。
スクレイピングした画像は機械学習で使用するためのものです。ここでは、スクレイピングした結果だけ記しています。
プログラム
BingImageCrawler
from icrawler.builtin import BingImageCrawler
#1---任意のクローラを指定
crawler = BingImageCrawler(storage={"root_dir": "菅井友香"})
#2---検索内容の指定
crawler.crawl(keyword="菅井友香", max_num=10)上記がプログラムになります。3行でスクレイピングして保存できることに驚きますね。
それでは解説していきます。
#1---任意のクローラを指定
crawler = BingImageCrawler(storage={"root_dir": "菅井友香"})1の部分ではクローラを指定しており、保存先のフォルダを指定しています。指定したフォルダが無い場合は作成してその中に保存されるようになっています。
#2---検索内容の指定
crawler.crawl(keyword="菅井友香", max_num=10)2の部分では検索するキーワードと数を指定しています。数の上限は1000になっているので注意が必要です。
he limitation is usually 1000 for many search engines such as google and bing. To crawl more than 1000 images with a single keyword, we can specify different date ranges.
https://icrawler.readthedocs.io/en/latest/builtin.html
結果
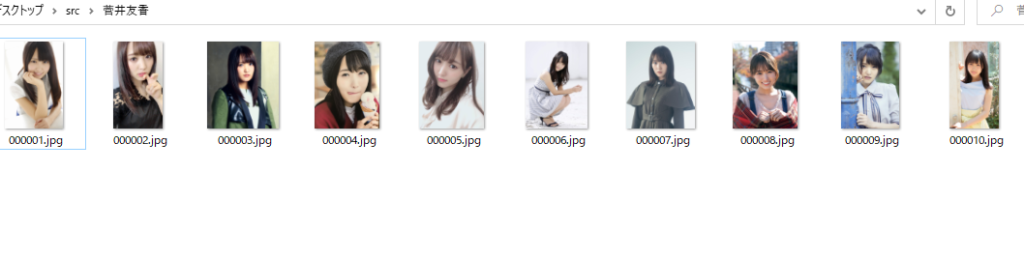
上記が結果です。しっかりとスクレイピングできていることが確認できました。
icrawlerを用いると簡単にスクレイピングできるので便利です。スクレイピングした内容を使用する場合は注意が必要ですが、便利なライブラリであることには間違いないですね。
GoogleImageCrawler
from icrawler.builtin import GoogleImageCrawler
def name(name_sel):
name = name_sel
crawler = GoogleImageCrawler(storage={"root_dir": name})
crawler.crawl(keyword=name, max_num=10)
name("ブルーピリオド")
name("絵画")関数化して任意の文字に該当する画像をスクレイピングしています。
適宜、ご参照下さい。
応用例 – 複数ワードで保存
keywords = ["犬", "花", "車"]
for word in keywords:
crawler = GoogleImageCrawler(storage={"root_dir": f"images/{word}"})
crawler.crawl(keyword=word, max_num=20)フォルダごとに分類されて保存されるので、データセット作成にも便利です。
保存先におすすめの機材
大量の画像を扱う場合は、外付けHDD/SSD や クラウドサーバー を活用すると便利です。