ここでは、欠損値の取得方法についてまとめています。欠損値を取得して穴埋めするまでの例としてkaggleの「titanic」を用いています。
この記事の対象
欠損値とは?
そもそも「欠損値」とはデータして不完全なものになります。
例えば、kaggleの「Titanic」trainデータを見てみます。この時、Ageの列に着目すると空欄がちらほらあります。この空欄などが欠損値となります。
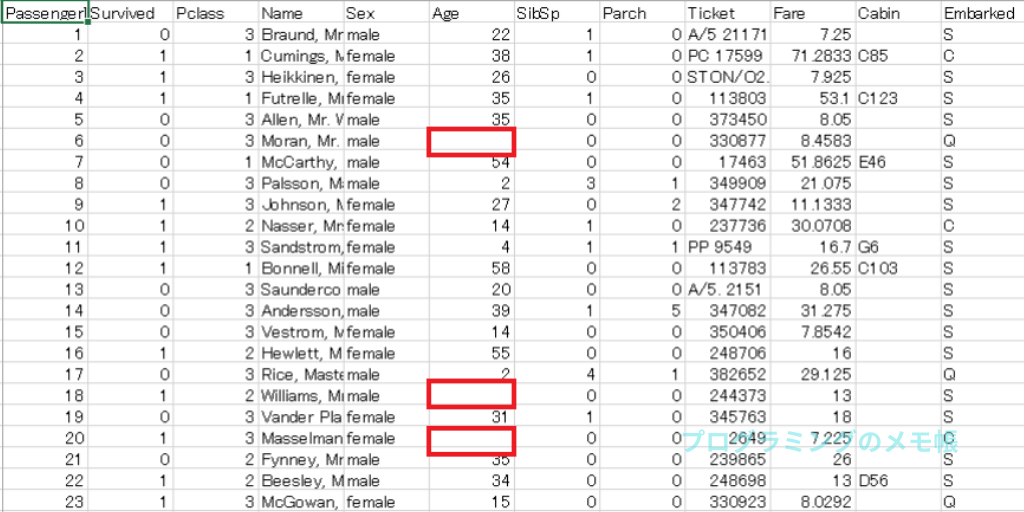
このままだと学習しづらいので、補完する必要があります。しかし、その前に簡単に可視化してどのぐらい欠損しているか確認します。
基礎統計(describe)
df.describe(percentiles=None, include=None, exclude=None, datetime_is_numeric=False)describeの簡単な概要です。
- percentiles:パーセンタイルの指定。
- include:結果に含める型を指定。
- exclude:結果から除外する型を指定。
- datetime_is_numeric:日時情報を数値化するかの指定。
それでは、雰囲気を掴むために一次分析として、pandasのdescribe()を用いて基礎統計量を算出してみます。
import pandas as pd
import numpy as np
df = pd.read_csv('train.csv')
train = df.describe()
name = "missing_value.csv"
train.to_csv(name,encoding="shift_jis")describeの特徴として、数値型以外の列は「include」「exclude」指定する必要があります。ここでは雰囲気を知りたいので、敢えて指定していないです。
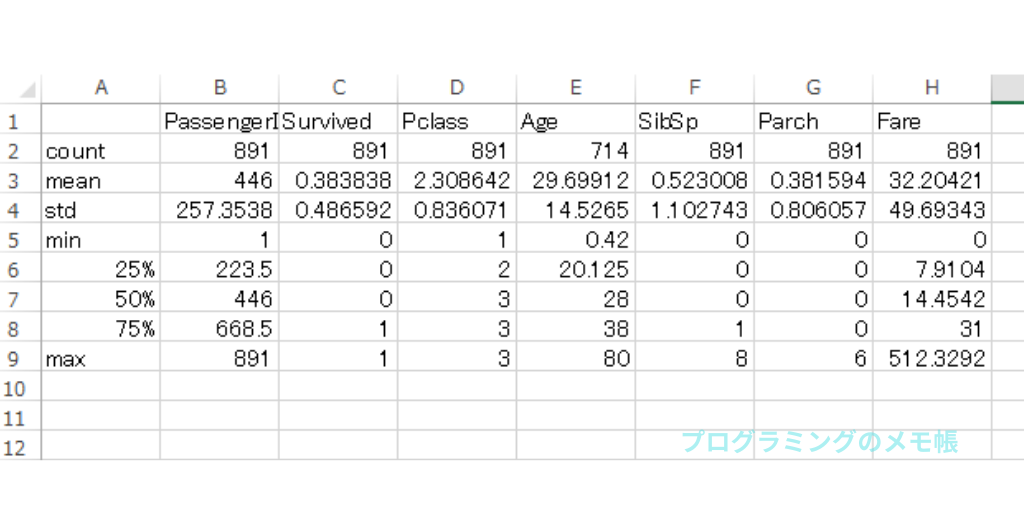
結果としては、Ageのcount(Data総数)が他の列に比べて少ないので欠損の確認ができました。
欠損値の可視化
欠損値を簡単に算出するプログラムです。引続きtitanicのtrainデータを用いています。
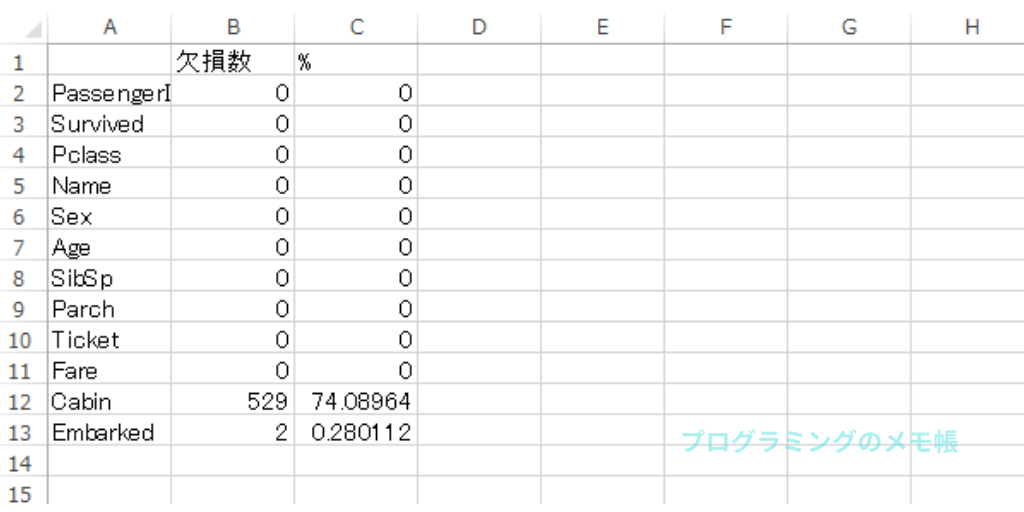
プログラムの内容としては欠損数と割合の算出になります。算出した内容は「csv」ファイルとして出力しています。
import pandas as pd
import numpy as np
df = pd.read_csv('train.csv')
#1---欠損値算出関数
def missing_value(df,num):
null_val = df.isnull().sum()#2---null
percent = 100 * df.isnull().sum()/len(df)#3---割合
missing_value = pd.concat([null_val, percent], axis=1)#4---結合
mv = missing_value.rename(columns = {0 : '欠損数', 1 : '%'})#5---列名
name = "miss" + str(num) + ".csv"
mv.to_csv(name,encoding="shift_jis")
#欠損値穴埋め前
missing_value(df,1)
#欠損値穴埋め後
df["Age"] = df["Age"].fillna(df["Age"].median())
missing_value(df,2)関数の内容を解説していきます。
null_val = df.isnull().sum()#2---null欠損値はpandasの「isnull」を用いて算出しています。「isnull」は要素ごとに欠損値か判定します。これを使って欠損値か判定して、3の部分で割合を出しています。
percent = 100 * df.isnull().sum()/len(df)#3---割合列中でのNaN要素の合計を長さ「len()」で割り、100をかけて、割合を算出しています。
4の部分ではデータの結合をしています。5の部分では列名を指定しています。最後にファイル出力しています。
結果
Age,Cabin,Embarkedが欠損していることが分かります。
欠損値の穴埋め
置換(fillna)
df.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None)fillnaの簡単な概要です。
- value:置換する値を指定。
- method:指定した値ではなく前後の値を指定。
- axis:置換する軸の指定。
- inplace:元のオブジェクト自体を変更。
- limit:最大何回まで連続して置換するかを指定。
- downcast:ダウンキャストの指定。
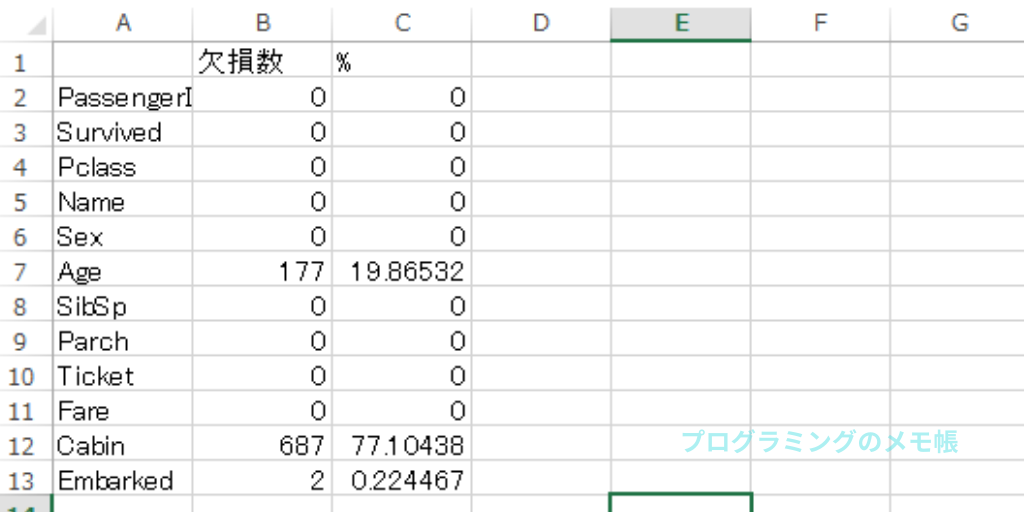
欠損値の置換は「fillna()」を用いることで簡単にできます。ここでは、穴埋めする対象は「Age」になります。また、穴埋めする値は、様々な分析をした上で決定する必要があります。今回は中央値を試しています。
#欠損値置換
df["Age"] = df["Age"].fillna(df["Age"].median())
missing_value(df,2)穴埋めする対象のAge列を指定して、「fillna()」の中にmedianを指定するだけです。次に関数化しているので、穴埋め後に読み出して確認しています。
結果
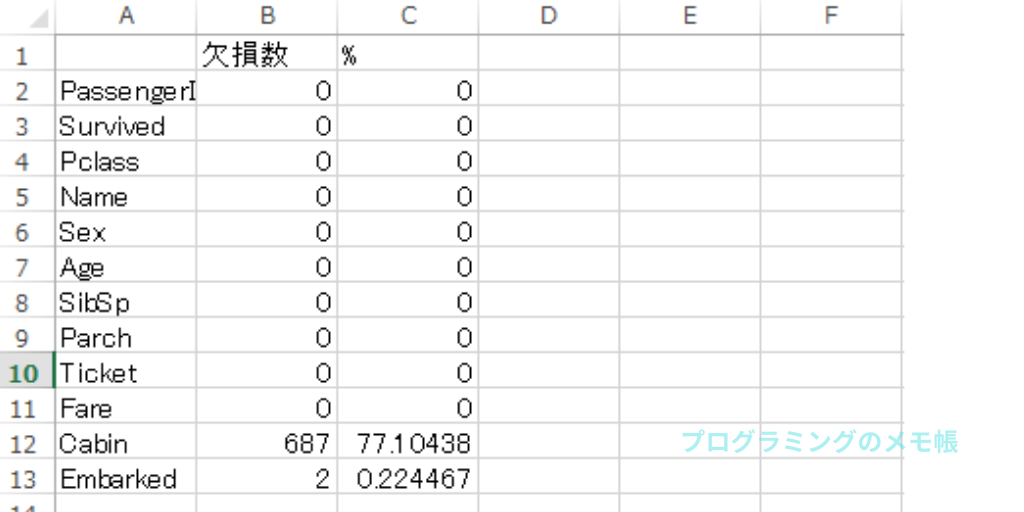
削除(dropna)
df.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)dropnaの簡単な概要です。
- axis:欠損している値を含む行または列を削除。「0」が行、「1」が列を削除。
- how:少なくとも1つのNAかすべてのNAがある場合に削除。「any」NA値が存在する場合に行または列を削除。「all」すべての値がNAの場合に行または列を削除。
- thresh:個数を指定すると欠損値ではない要素の数に応じて行・列を削除。
- subset:特定の行・列に欠損値がある列・行を削除。
#欠損値削除
df= df.dropna(axis=0,how='any',subset=['Age'])AgeのNaNを元に行を削除しています。
結果